

[Originaltitel: „As Above, So Below“]
Ich habe den besten Wissenschaftsjob der Welt. Ich kann forschen, was ich will, wann ich will, so lange ich will, und ich bekomme keinen Cent, egal wie hart ich arbeite. Was kann man daran nicht mögen?
Auf jeden Fall habe ich mir überlegt, wie viele Temperaturstationen wir brauchen, um eine genaue Vorstellung von der Durchschnittstemperatur der Erde zu bekommen. Da ich eher ein Datenmensch, denn ein Theoretiker bin, dachte ich mir, dass ich den CERES-Datensatz verwenden könnte, um einen ersten Versuch zu wagen, diese Frage zu beantworten.
Vorab möchte ich den Temperaturdatensatz erläutern, den ich für meine Analysen verwende. Die CERES-Strahlungsdatensätze enthalten keinen Temperaturdatensatz. Sie enthalten jedoch einen Datensatz für die aufsteigende langwellige (thermische) Strahlung an der Oberfläche. Da viele meiner Analysen den CERES-Datensatz verwenden, habe ich den CERES-Datensatz für die Oberflächenstrahlung benutzt, um einen Datensatz für die Temperatur zu erstellen. Für die Berechnung habe ich die Stefan-Boltzmann-Gleichung verwendet und den gerasterten Oberflächen-Emissionsgrad von hier genutzt.
Wie gut ist der mit CERES berechnete Temperaturdatensatz? Hier ist ein Vergleich mit den Datensätzen von Berkeley Earth, HadCRUT und der Japanischen Meteorologischen Agentur. Saisonale Schwankungen wurden aus allen Datensätzen entfernt:
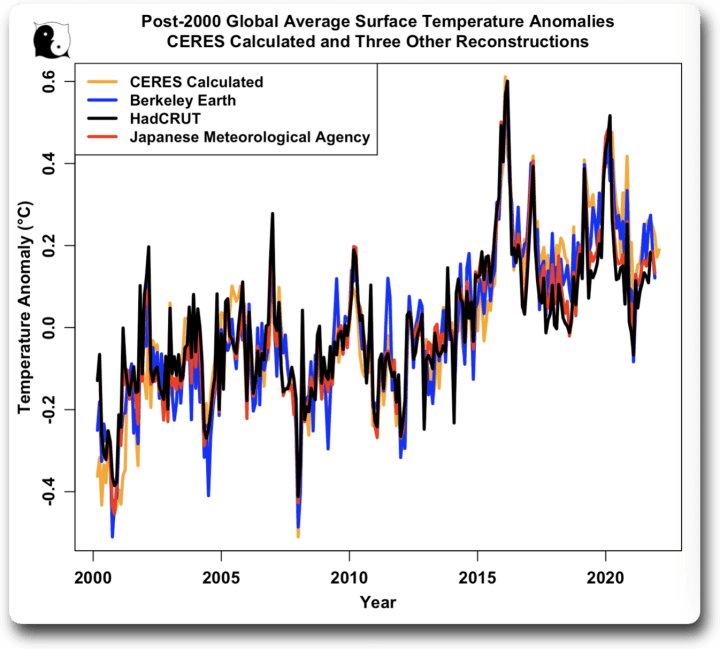
Wie man sieht, stimmt die berechnete CERES-Temperatur mit den anderen drei Daten überein, und sie stimmen auch untereinander überein. Es stellt sich heraus, dass sie auch besser mit dem Berkeley Earth-Datensatz übereinstimmt als der HadCRUT- oder der JMA-Datensatz… daher verwende ich die CERES-Daten in dieser und meinen anderen Analysen. Wie aus dem obigen Diagramm hervorgeht, macht es jedoch keinen praktischen Unterschied, welcher Datensatz verwendet wird. Wenn man die folgende Analyse mit dem Berkeley-Earth-Temperaturdatensatz durchführt, erhält man im Wesentlichen die gleichen Ergebnisse wie mit dem CERES-Datensatz.
Nach diesem Prolog bestand mein Plan darin, zufällig eine Teilmenge der 64 800 Gitterzellen mit 1° Breitengrad und 1° Längengrad auszuwählen, aus denen die Erdoberfläche besteht, und zu sehen, was diese Teilmenge als Durchschnittstemperatur ergab.
Die interessantesten Ergebnisse ergaben sich, wenn ich nur ein Prozent der Gitterzellen (n = 648) verwendete. Hier ist ein Beispiel für eine zufällige Auswahl von 1 % der Gitterzellen:
Wie man sich vorstellen kann, ergaben sich bei mehrmaliger Ausführung des Zufallsbeispiels sehr unterschiedliche Durchschnittstemperaturen aus verschiedenen zufälligen Teilmengen von 1 % der Gitterzellen. Hier ist ein Histogramm der Durchschnittstemperaturen eines typischen Laufs von 100 Versuchen mit nur 1 % der Gitterzellen:
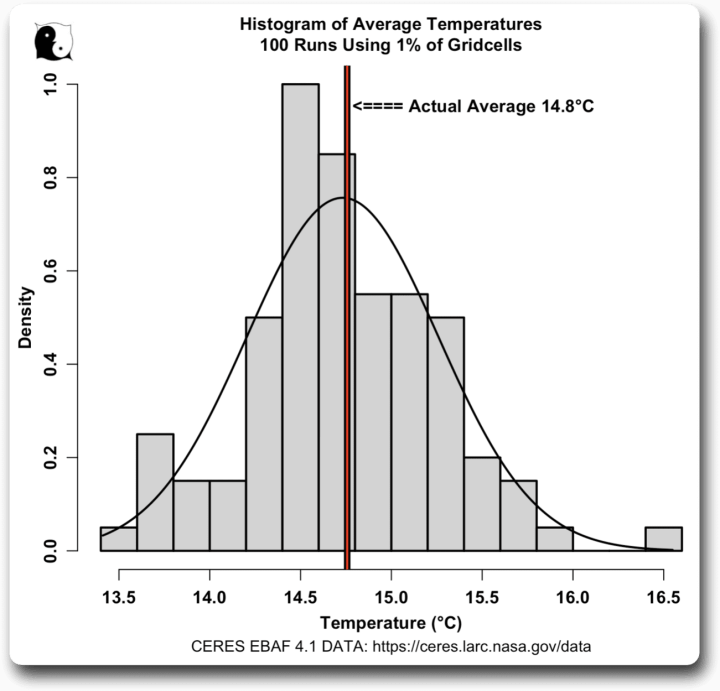
Die Durchschnittstemperaturen liegen zwischen 13,5 und 16,5 Grad, so dass es kaum Übereinstimmungen zwischen den Teilmengen gibt. Keine Überraschung, wie ich sagte.
Aber meine nächste Grafik war eine Überraschung. Ich beschloss, die monatlichen Daten für einige der einzelnen Läufe aufzuzeichnen. Hier ist ein Beispiel von zehn Läufen, einschließlich der linearen Trendlinien. Ich habe die saisonalen Schwankungen aus den einzelnen Datensätzen entfernt:
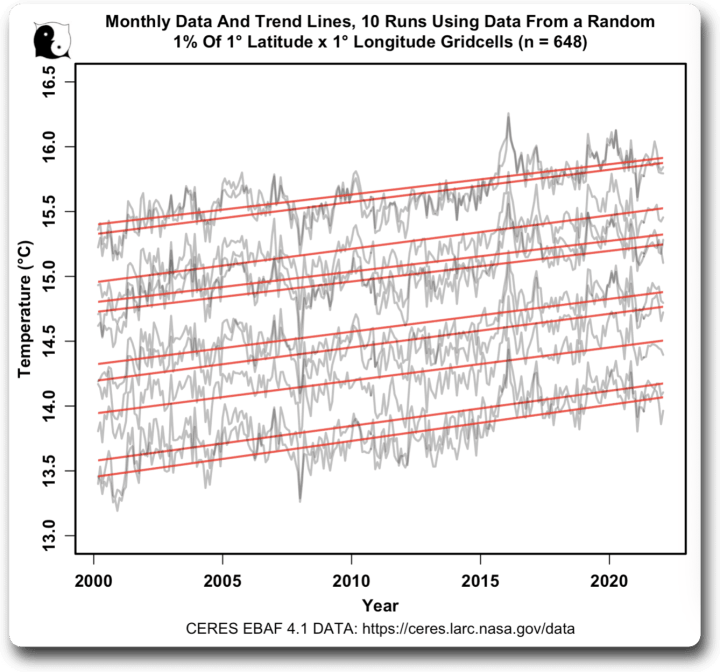
Zwei Dinge waren dabei überraschend. Zum einen waren die Trends alle ziemlich identisch. Ich hatte viel größere Unterschiede erwartet, wenn man nur 1 % der Daten verwendet.
Die andere war, dass die tatsächlichen monatlichen Ergebnisse alle so ähnlich waren, mit der gleichen Gesamtform, nur mit einer anderen Durchschnittstemperatur.
Um das weiter zu untersuchen, habe ich die Anomalien für jeden der Läufe aufgezeichnet. Ich erstellte die Anomalien, indem ich den Durchschnitt eines jeden Laufs von den Werten des jeweiligen Laufs subtrahierte. Hier sind die Ergebnisse:

Faszinierend. Obwohl wir aus 1 % der Daten nicht viel Klarheit über die absolute globale Durchschnittstemperatur gewinnen können, können wir das gleiche 1 % der Daten verwenden, um eine ziemlich gute Vorstellung vom Gesamttrend und den monatlichen Schwankungen der globalen Durchschnittsdaten zu bekommen. Keiner der einzelnen 1 %-Läufe weicht wesentlich vom globalen Durchschnitt ab, und ihre Trends liegen eng beieinander. Das hatte ich überhaupt nicht erwartet.
Als Nächstes dachte ich über die oft wiederholten Behauptungen nach, dass die Kleine Eiszeit in den Jahren 1600 bis 1700 nur ein Phänomen der nördlichen Hemisphäre war oder dass sie nur auf Aufzeichnungen vom Festland basierte, oder beides. Also warf ich einen Blick auf die Landdaten der nördlichen Hemisphäre, um zu sehen, wie zufällige Teilmengen von Landdaten der nördlichen Hemisphäre mit den globalen Daten übereinstimmen. Da die Landfläche der Nordhemisphäre viel kleiner ist als die der Erde und es sich um Land und nicht um Ozean handelt, sind die Temperaturschwankungen der durchschnittlichen Landtemperatur in der Nordhemisphäre natürlich größer als die Schwankungen des gesamten globalen Durchschnitts. Um einen Vergleich zu ermöglichen, habe ich dies in der folgenden Grafik berücksichtigt:
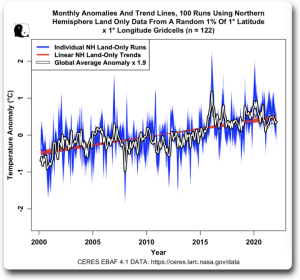
Auch das ist höchst interessant. Mit der Kenntnis der Temperatur in etwa hundertzwanzig zufällig ausgewählten Gitterzellen der insgesamt 64.800 Gitterzellen, wobei sich die bekannten Gitterzellen nur auf dem Land befinden und weniger als ein Viertel eines Prozents der Erdoberfläche abdecken, können wir sowohl die globale Temperaturanomalie als auch den globalen Temperaturtrend genau annähern.
Jeder einzelne Durchlauf mag eine exakte Übereinstimmung mit dem gesamten Globus sein oder auch nicht, aber keiner von ihnen unterscheidet sich wesentlich, und ihre Trends variieren nur geringfügig … was mich an dem Gedanken zweifeln lässt, dass die Kleine Eiszeit ein lokales Phänomen war.
Es scheint eine Bestätigung dessen zu sein, was ich bescheiden „Willis‘ erste Klimaregel“ nenne, die besagt:
„Im Klima hängt alles mit allem zusammen, was wiederum mit allem zusammenhängt … außer wenn das nicht der Fall ist.“
Link: https://wattsupwiththat.com/2023/10/21/as-above-so-below/
Übersetzt von Christian Freuer für das EIKE
Anmerkung der Redaktion:
Bevor nun jemand in Freudentränen darüber ausbricht, wie präzise doch CERES Strahlungsdaten und Thermometwermessungen übereinstimmen, sei etwas Wasser in den Wein der Freude geschüttet.
Erstens: Willis‘ Datensatz beginnt erst im Jahr 2000. Die Hinweise bswp von Pat Fank und M. Limburg aber auch andere beziehen sich auf Daten für Temperaturen und Sensoren des 19./20. Jahrhunderts. Vor dem Satelliteneinsatz.
Zweitens: Die drei Oberflächentemperaturtrends sind keine Rohdaten. Es sind angepasste und damit manipulierte Daten. Niemand weiß, was sie tun, um ihre Rohdaten in endgültige Daten umzuwandeln. Möglicherweise gibt es sogar Anpassungen, die die Rohdaten mit den TOA-Emissionen in Einklang bringen. Wir wissen es nicht.
Außerdem handelt es sich bei CERES auch nicht um reine Daten. Auf dieser Seite, https://ceres.larc.nasa.gov/science/, heißt es zum Beispiel in der Abbildung „CERES-Messungen der planetaren Wärmeaufnahme“ darunter: „Kumulative planetarische Wärmeaufnahme von CERES. Eine einmalige Anpassung an CERES.“ Der globale mittlere Netto-TOA-Fluss für den Zeitraum 07/2005–06/2015 wurde angewendet, um die Konsistenz mit dem In-situ-EEI im gleichen Zeitraum sicherzustellen.“ Eine einmalige Anpassung, um zwei Datensätze in Übereinstimmung zu bringen! Dies bedeutet wahrscheinlich, dass ein Versatz nach oben oder unten angewendet wurde. Woher weiß man, dass sie die richtige Entscheidung getroffen haben?
")

